
SKYPCEが、お客様からお預かりした名刺画像を基に情報をデータ化する上で欠かせないのがOCR(光学的文字認識)の技術。AIを用いた画像認識技術によって大幅に精度が向上したAI-OCRとはどのような技術なのか。さらにAIや画像認識技術の未来について、画像認識技術の第一人者である中部大学 藤吉 弘亘 教授とSKYPCE開発の中心的役割を担う開発者による座談会を開催しました。

藤吉 弘亘 氏
中部大学 工学部 教授
日本ディープラーニング協会 理事
1997年、中部大学大学院博士後期課程修了。米カーネギーメロン大学ロボット工学研究所Postdoctoral Fellow(1997年)、中部大学工学部情報工学科講師(2000年~)、同大学准教授(2004年~)、米カーネギーメロン大学ロボット工学研究所客員研究員(2005年~2006年)、中部大学教授(2010年~)、名古屋大学客員教授(2014年~)。コンピュータビジョンの研究に従事。

まず、SKYPCEのデータ化フロー 図1 をご覧ください。お客様がスキャナーやiPhoneを使って取り込んだ画像は、お客様組織内のSKYPCEサーバーとSkyクラウドサーバーを経由して、弊社のサーバーに送られます。その後、オペレーターの作業用PCに転送されてからOCRを実行します。
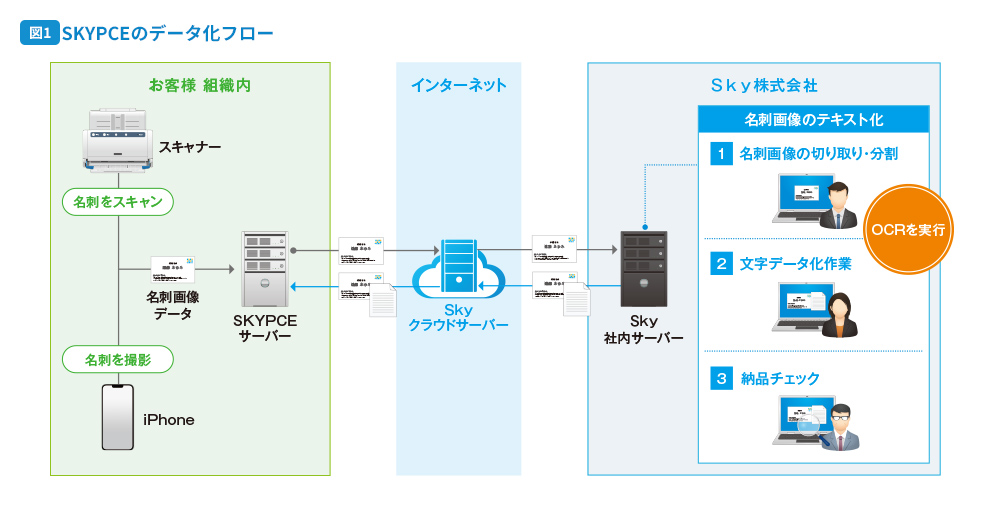
この段階まではデータを暗号化して通信する以外に、OCR用の画像加工処理などは行っていません。
OCRの結果はSKYPCEに反映されるので、目視でチェックして誤りがあれば修正し、その後に納品チェックを経て、データを逆流させる形でお客様のサーバーにお返しするという流れです。
名刺のような書式が決まっていない印刷物の場合、OCRの難易度が高いのですが、実際のところ精度はどの程度ですか?
私もOCR結果を見て修正する作業をしてみたのですが、正直なところ、現時点ではOCRだけでデータを確定させるのは難しいという印象を持っています。今後の技術向上によって、OCRだけで100%の精度を目指せるものなのでしょうか。
詳しくは後ほどご説明しますが、結論から言えば100%の精度を担保するのは難しいと言わざるを得ません。
そもそも、OCR自体は歴史が古い技術で、1960年代には郵便番号の読み取り、仕分け作業の効率化を目的に実用化されたもので、近年はAI(ディープラーニング)を用いた画像認識技術によって精度が上がっているのですが、まだ課題も少なくありません。
郵便番号の読み取りから始まったんですね。ということは、初めから手書き文字を認識することを前提に開発されたものなんですね。
そのとおりです。もしフォントが統一されていれば、単純なパターンマッチングでも識別できます。手書きの場合は、人によって筆跡が異なりますので、文字の特徴をどのように読み取って認識するのかが開発の出発点でした。
まず、従来型OCRの主な流れをご説明します。図2 をご覧ください。まず初めに「① 傾き補正」を行います。画像からエッジを抽出して直線を検出、その傾きを補正します。郵便番号なら番号の枠、名刺なら名刺台紙の端などの直線を基に補正することになります。

続いて「② レイアウト解析」という処理をします。画像内の画素をすべて白(0)と黒(1)の2値に分けます。そこから文字の塊となる部分を認識して矩形領域として切り出します。
ここで、すべての文字が白地の上に記載されているのであれば問題はないのですが、イラストや写真と重なっていると、途端に難易度が上がってしまいます。
そうですね。名刺の文字認識はそういった点も阻害要因の一つになります。続いて、切り出した矩形領域から2値化された画素データを基に「③ 1文字ずつ切り出し」を行ってから、ようやく「④ 文字認識」となります。
前処理の段階で、正確に個々の文字を切り出すことが大切なんですね。
そうです。例えばレイアウト解析でつまずくと、その後の処理がすべてうまくいかなくなりますので、前段の精度の向上も必要です。
文字認識フェーズでは、文字の大きさをそろえる正規化をした上で、方向別ヒストグラムを基にした特徴抽出などを行って、文字を認識します。さらに「⑤ 知識処理」を加えます。例えば「東京都」という文字列のうち「京」の文字が欠落していたり、誤認識されていたりしても、1文字目の「東」と3文字目の「都」の間に「京」が入るべきと推定して、2文字目を補完することで精度を上げています。
見積書や請求書といった帳票など、書式がある程度決まっている場合は従来型のアプローチでもうまくいくことが多いと思います。
しかし、名刺は大きさこそ規格があり一部を除いて一定ですが、デザインはまさに千差万別です。レイアウトもセオリーがあるようでなかったり、ロゴマークだけでなくイラストや写真が使用されていたり、縦書きと横書きが混在しているものもあります。
そのように書式が一定ではなく複雑なレイアウトのものを、2値化ベースで処理すると文字領域を正確に切り出せないというのが、従来型OCRの課題でした。
大量のデータから学習するディープラーニングの技術を使うことで、文字領域の切り出し精度が飛躍的に向上しています。
ディープラーニングによる「物体検出」であれば、画像内に何が映っているのかを見極めることができますので、それを活用して文字とそれ以外の要素を分類できます。また、文字を認識する部分も「畳み込みニューラルネットワーク(CNN)」という方法で性能を大幅に向上させることができます。
なるほど。基本的な流れは従来型と大きく変わらないが、それらのポイントとなる部分の精度向上にディープラーニングが役立っているわけですね。
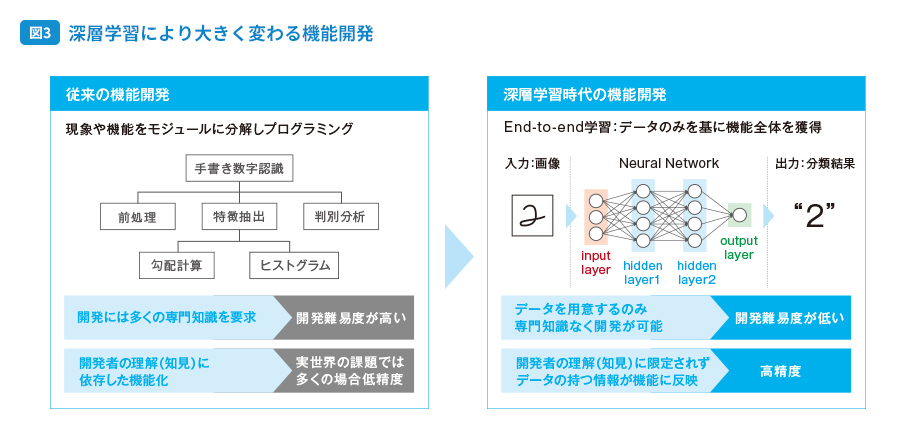
そうですね。そのほかに、機能開発のアプローチも従来とは異なります。図3 をご覧ください。従来は、現象や求める機能をモジュールに分解し、それぞれにプログラミングを行っていました。これは、複数の画像認識技術を人の手で組み合わせて機能として仕上げているようなイメージです。
一般的なソフトウェアの開発と同じですね。
しかし、この方法ではモジュールごとに非常に高度な専門知識が必要になる上、得られる性能が開発者の知見の範囲に依存してしまうため、実際に起こり得るさまざまな課題にうまく適用できず、精度が低下してしまうことが少なくありません。一方でディープラーニングでは「End-to-end学習(用語解説)」という手法で、データのみを基に機能全体を獲得します。
用語解説:End-to-end学習
入力データから結果を出力するまでに、複数のモジュールによる処理を必要としていた従来の機械学習システムを、さまざまな処理を行う複数の層・モジュールを備えた一つの大きなネットワーク(ニューラルネットワーク)に置き換えて学習すること。
つまり、図3 の左側のように勾配計算やヒストグラム解析を行うことで特徴抽出するのではなく、「どうのように文字を認識するのか」という機能そのものを学習によって獲得するということですね。
なるほど。それなら開発者の知見に依存することなく、データから得た情報によって性能を向上させることができるということですね。
決して簡単ではないですが、従来のモジュールごとの機能開発に比べて、開発難易度はかなり低くなったと言えるのではないでしょうか。
データから学習するという点で機能開発の難易度が下がったとはいえ、データから学習するには、正解を与える必要もあります。それをずっとやり続けたとしても最終的に精度が100%に到達するかといえば、残念ながら難しいと思います。
もし仮に、全世界に存在する名刺をすべて学習させることができれば実現できるのかもしれませんが、それは現実的ではありませんね。
しかし、これまではすべての項目を手作業で入力していたことを考えると、作業効率は格段に向上できると思いますし、現在も残るさまざまな課題をクリアしていくことで精度向上は図れると思います。
現在の技術レベルでも、90%くらいは正しく認識できるものでしょうか。
レイアウト解析がうまくできていることが前提ですが、90数%以上の精度は見込めると思います。
なるほど。SKYPCEの命題としては、限りなく100%に近い精度でデータを提供することが求められますので、やはりオペレーターによる目視確認と修正という人の手は欠かせないことなのですね。
認識結果に対する信頼度がわかりますので、例えば信頼性が低い部分を重点的に見るなど、確認作業を効率化する方法もあるとは思います。逆に、OCRによって精度100%の結果を得るのは難しいということを前提として考えるなら、それにどのように対応するのかが、サービスとしての良し悪しや信頼度を決めるポイントになるのかもしれないですね。
より良いデータで、学習モデルを更新して精度を高めるといったことも大切ですね。
もちろん、それもあります。システムは作って終わりではなく、使うほどに精度を高めていけると思いますので。さらに、先ほどは従来型OCRでも知識処理を行っていると説明しましたが、的確に補完できるようになるには、まだ多くの課題が残っていますので、精度を上げる余地はたくさんあります。また、後処理だけではなく入力データの質を高めることも、その一つです。
現在、スキャン時の解像度は300dpiとしています。iPhoneの場合は、撮影時の環境によって多少前後するようですが、おおむね同じくらいです。
文字を認識するという観点でいえば、1文字あたり20画素くらいあれば十分だと思います。名刺の中で最も小さな文字ってどのくらいの大きさなのでしょうか?
おそらく5ポイントくらいですね。ですから、文字幅がおよそ1.76mmとして、300dpiであれば……20.81。ちょうど20画素くらいですね。
私の方で、解像度を2倍、3倍に引き上げてOCRを試したことがあるのですが、良くなる部分と悪くなる部分の両方がありました。例えば、メールアドレスや携帯電話の番号などの最も小さな文字では、2倍に上げると精度は向上するようです。
逆に悪くなるというのは、どういったところですか。
レイアウト解析では認識がうまくいかず、精度が低下する場合がありました。また、文字認識でも2倍程度なら精度向上が見込めますが、3倍にしてもそれ以上は上がらない印象です。逆に、拡大することで余計な汚れなどを拾いやすくなり、精度が低下するケースもありました。
解像度を上げることは通信量の増大にもつながりますので、この辺りはバランスを取る必要がありますね。クラウドサーバーを介してデータをやりとりするため、通信量の増大はコストに直結しますので。
そうですね。画素数が増えると計算量も増大しますので、レスポンスに影響が出ることも考えられます。適切な入力は解くべきタスクによって異なります。例えば、文字領域の切り出しは、住所であれば住所っぽい文字列を見つけられればいいわけです。
顔検出でも同じですよね。一人ひとりを厳密に見分ける必要があるなら高解像度の画像が必要ですが、人の顔を見つけるだけなら低解像度でもいい。
技術的アプローチで精度を向上することだけではなく、通信コストやレスポンスも考慮したバランスが、サービス全体として品質を決めるということですね。
そもそも、名刺は印刷品質がそれほど高くないものも多いです。初めから小さな文字がつぶれてしまっているものもありますし、紙の光沢が強いためスキャンや撮影の際に反射して、画素が白く飛んでしまう場合も少なくありません。
OCRエンジンの精度はもちろん重要ですが、より良い状態のデータを使用することも大切です。前段として、OCRが認識しやすいものに加工してあげることもできますね。
現在、文字領域を抽出する際に、あらかじめ物体検出を使って文字列以外のロゴマークやイラストなどを除外する(白く塗りつぶし除去する)ことに取り組んでいます。実装はまだこれからですが、秋までには活用できるようにしたいと考えています。
名刺には会社のロゴマークをはじめ、顔写真や認証取得マークなどが記載されていたり、自治体では公式ゆるキャラのイラストなどが印刷されていたりします。今後の画像認識技術の向上によって、名刺情報として扱う要素と、そうでない要素を分けることで確実に精度が上がるだろうと期待しています。図4

前処理としてデータを加工して、必要な情報だけに絞ってOCRにかけることで、精度はもちろんレスポンスにも好影響があると思います。また、併せてOCRの結果に対して後処理として、データを訂正することも大切です。文字認識フェーズはもちろん、その前と後がとても重要になります。
SKYPCEは現在、名刺に特化した他社製のOCRエンジンを使用しているのですが、同じエンジンでも前後の処理によって違いが出るということなんですね。
例えば、自治体の名刺だとスローガンが記載されていたり、認証取得マークには説明のテキストが添えられていたりしますよね。先ほどのマークやイラストの場合であれば、物体検出で分類することが可能ですが、こうした文字列をどのように扱うかが難しいところです。
項目の振り分けはOCRエンジンに依存するので、スローガンを住所と間違えて振り分けてしまっているというケースも、少なからず発生しています。
そうした点はまだ大きな課題ですし、改善の余地が残されていると思いますので、今後も対策を考えていきたいと思います。
どういったケースが間違いやすいかを、しっかり分析することが重要ですね。ディープラーニングはデータから学習することが前提ですから、結果分析に基づいて学習させるサイクルが回せる体制を整えることが求められます。
現在は、オペレーターが修正した正しいデータと名刺画像をAI担当に渡して、傾向を分析してもらっています。
私の方で、あらためて名刺画像をOCRにかけ、その結果とオペレーターの修正済みデータとを突き合わせて差分を確認しています。2つのデータの整合率が100%なら問題なし、90%程度なら文字の一部が誤認識をしているといった傾向がわかります。
中には全然合っていないというケースもありますよね。
はい。20%や0%ということもあります。こうした場合は、レイアウト解析のフェーズでつまずいていて、それ以降の処理がすべて失敗しているというケースだと考えられます。
そうして分析した結果から傾向がわかると、それを再現して新しいデータを自動生成することもできますので、そのデータを学習させてさらに精度を高める。繰り返しになりますが、1回作れば終わりではなく改善のサイクルを回していくことが重要です。
そういう意味では、OCRエンジンが同じものであっても、それ以外の部分で学習のサイクルをしっかり回すことによって、精度が高められるということですね。
そのとおりです。「データセントリックAI(用語解説)」という考え方があり、AIの学習モデルを改良するのではなく、入力するデータの質を高めることで従来の学習モデルであっても精度を高めることができるとされています。
用語解説:データセントリックAI
従来のAI開発の主流であったAIの学習モデル改善ではなく、どのようなデータを追加して修正や変更を加えれば、AIの精度向上が図れるのかという観点で取り組むAI開発の考え方。
データセントリックAIとは少しアプローチが異なりますが、過去にSKYPCEに取り込んだ名刺(既存名刺)を活用して、同じ名刺であれば処理をスキップするという機能の開発にも取り組んでいます。
この先、SKYPCEの市場シェアが上がると必然的に重複する名刺も増えるので、同じ名刺ならOCRの処理が省略できるという考え方ですね。さらに、同じ会社の方なら名刺台紙のレイアウトは似通っていると考えられますから、部署や名前、個人の連絡先だけをOCRにかけることもできるのではないかと期待しています。
今はまだ、AIを動かすための環境づくりをしているところですが、膨大な既存名刺データと新規に取り込んだ名刺の画像の類似点を見つけて、同じものかどうかを判断する仕組みを作りたいと考えています。この辺りの作り込みについては藤吉教授にもご助言をいただきながら進めていきたいと思っています。
もちろん、できる限り協力させていただきますので、ぜひご相談ください。
AIというと、一般的なイメージとして「人と対峙する存在」のように扱われることがあると思うんですね。例えば、将来は人の職が奪われるとか。
確かに。少し前はそういう文脈で語られることが少なくなかったですね。
私は、むしろAIは「人に寄り添っていく存在」だと考えています。特にこれからは、そうでなくてはならないと思います。
藤吉教授のご専門は、AIの判断根拠の可視化ですが、それに関係するのでしょうか。あ
そうですね。AIが何かしらの判断を行う場合、多くの場合がそのプロセスはブラックボックスとして扱われています。しかしAIを使う人(使用者)にとって、AIが本当に信頼できるものであるかを見極めるためには、AIが下した判断の根拠が説明できなければいけないと考えています。
判断の根拠というのは、どういう部分で説明できるのでしょうか。
「アテンションマップ」というものがあります。これは、AIが判断を行う際にどの範囲に注目をしているのかを、ヒートマップを用いて示すものです。例えば、自動車の車種を識別する際、AIはテールランプの形状に注目しているといったように、人の判断に近い着眼点で識別していることが可視化されます。具体例として、眼底画像による診断のケースをご説明します。 図5
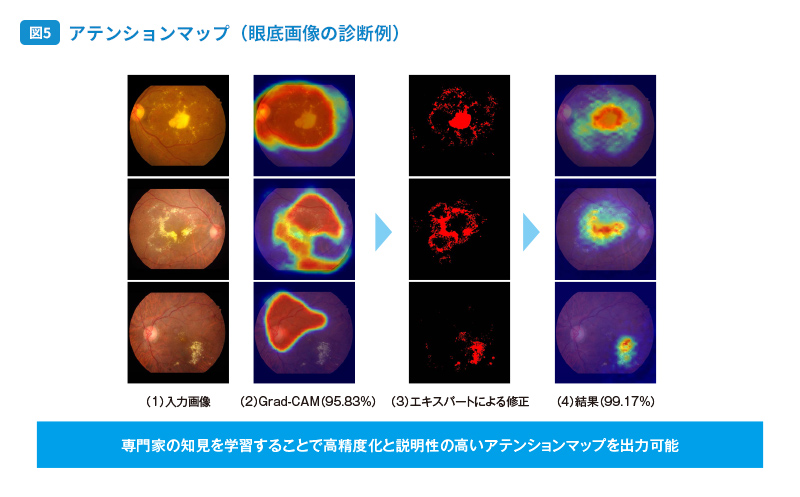
図の左が、検査によって撮影された眼底の画像(1)ですね。
はい。この例に挙げた3例はすべて疾患を有している患者の画像です。そして、AIは3つとも疾患の可能性ありと判断しています。
AIによる診断が正しい結果だったということですね。
しかし、通常のAIモデルの判断根拠をGrad-CAMというツールを用いて作成したアテンションマップ(2)を見ると、必ずしも疾患部分だけに注目して疾患の有無を判断しているわけではないことがわかります。むしろ正常な部位を見て疾患だと判断している可能性も残るわけです。
それは、的確な根拠に基づいていなくても、正しい答えを導き出すケースがあるということでしょうか。
そうです。この実験では95.83%の精度が出ています。しかし、こうした根拠がわれわれ人間にとって適切でない状態では、そのAIの判断が本当に信頼できるものかと問われた場合、疑問を持つ方が多いのではないかと思います。
ですから、判断の根拠がどこにあるのかを可視化するということが大事なのですね。
さらに、アテンションマップの右隣の画像(3)をご覧ください。これは、眼底画像の診断に長けたエキスパートの医師が、これらの画像における疾患部位はここだと赤色で示したものになります。そしてAIにそれを伝えるわけです。
エキスパートの知見によって、AIがさらに学習するということですね。
はい、エキスパートの知見をAIに組み込むことを意味します。その結果、一番右の画像(4)のように疾患部分を適切に見極められるようになり、99.17%の精度で疾患だと判断できるようになりました。
人の知見が組み込まれることにより、人にとってより根拠がわかりやすく、扱いやすいAIとなるということですね。「AIが人に学ぶ」という表現になるのでしょうか。
そうですね。その逆に「人がAIに学ぶ」ということもあります。先ほどの眼底画像に基づいた診断を例にすると、エキスパートの知見が組み入れられたAIを使って、研修医などの学習者が疾患を見極めるための教育アプリケーションを作るといったことができます。
エキスパートの知見を体現したAIを活用して、研修医の方の判断が正しいかどうかを採点するようなものですね。
はい。簡単に説明すると、まず研修医の方が眼底画像だけを頼りに疾患だと思われる部位を指定します。それが適切かどうかをAIが判断してインタラクティブにスコアへ反映します。何度も繰り返して、的確な部位を示せるようになればスコアが上昇するというものです。
言葉が適切かどうかわかりませんが、まるでゲームを行っているようなイメージですね。
確かにゲーム的な要素はあると思います。この実験では知見を組み込んだAIアプリケーションを使った学習者の正答率が上がり、さらに標準偏差も小さくなっていることからも、十分な教育効果が見込めると思います。
AIが人の知見によって学ぶことで質を高め、さらにそのAIから人が学ぶことで知見を継承するというサイクルが成立するということなのですね。
つまり、AIと人は共に高め合いながら進歩することが可能だと、私は考えています。決してAIだけが独立した存在ではないということです。
今回の例は、医療分野での画像を用いた診断でしたが、そのほか多くの分野でも応用できそうですね。例えば、生産工場における外観検査であるとか。
私もそう思います。例えば熟練工の技術を学ぶ上で、そのエキスパートの視点がどこにあるのかをAIが学び、そのAIによってより多くの研修生が学べるようになるのではないかと思います。
弊社では、クライアント・システム開発事業本部において、自動車関係を中心に医療や工場関係など幅広い分野で、AIを用いた画像認識技術を活用したシステムの開発に取り組んでいますので、今お話しいただいたような点についてもお客様に提供していけるのではないかと思います。
今はまだAIというものが、何か特別な技術のように捉えられがちですが、いずれは生活の一部として当たり前に存在するものになっていく必要があると思います。
インターネットも当初は特別なものでしたが、今はその仕組みを理解していなくても、非常に多くの方が活用して生活を豊かにしています。きっと、それと同じように、より身近な技術になっていくのでしょうね。
スマートフォンなどの顔認証システムなどは、その代表的な例だと思います。今後はさらに多くの分野でAIが人の生活をサポートしていく時代になっていくと思います。
お話を聞いて、われわれのような企業や組織における作業の効率化に、当たり前のように生かされていく未来が、もうすぐそこにあるんだと実感できました。
作業の効率化と同時に、人が犯しやすいケアレスミスを補うようなことも大切ですね。いずれにせよ、AIは「人と対峙する存在」ではなく「人に寄り添う存在」だということをご理解いただければ幸いです。
(「SKYPCE NEWS vol.3」 2022年7月掲載 / 2022年6月オンライン取材)
名刺管理のSKYPCEについて詳しくはこちらから