
OpenSearchが提供するシノニム機能の概要と、SKYPCEの「会社名かな・同義語検索」機能で、あえて別の実装を選択した技術的背景を解説します。データパイプラインの整合性や、kuromoji(形態素解析)との相互作用といった観点から、最適な技術選定のプロセスを深掘りします。
SKYPCE開発チームです。
私たちのSKYPCEは、その基盤技術の一部にAWS OpenSearch Serviceを採用しており、日々そのパワフルな検索能力に助けられています。
さて、以前のブログでご紹介した「会社名かな・同義語検索」機能ですが、その開発過程で、私たちはOpenSearchが提供する「シノニム機能」という、非常に魅力的な機能の採用を検討しました。
今回は、このOpenSearchシノニム機能がどのようなもので、どのような可能性を秘めているのかをご紹介するとともに、なぜ最終的にSKYPCEの会社名検索の特定要件においては、別の実装を選択したのか。
その技術的意思決定のプロセスについて、少し深くお話ししてみたいと思います。
1. 「検索体験の向上」とOpenSearch
SKYPCEがお客様の業務効率化を支援する上で、「検索」は極めて重要な要素です。
私たちは、曖昧な記憶からでも目的の情報へ最短でたどり着ける、ストレスのない検索体験を常に追求しています。
その追求の過程で、OpenSearchが提供する多彩な機能は、開発チームにとって力強い味方です。
今回焦点を当てる「シノニム機能」も、当初、本機能の要求を簡単に解決してくれる有力な候補でした。
2. OpenSearchシノニム機能の紹介とその可能性
OpenSearchのシノニム機能とは、検索時に、ある単語を別の単語と「同義」として扱わせるための仕組みです。
この機能の核心は、テキスト解析(Analysis)のプロセスに「Synonym Token Filter」または「Synonym Graph Token Filter」を組み込むことにあります。
これにより、既存の検索ロジックや検索キーの再選定をすることなく、インデックス作成時または検索時に、指定された同義語への変換や展開が自動的に行われます。
例えば、以下のルールをテキストファイル(シノニム辞書)に定義し、それをインデックス設定に紐づけます。
"SKYPCE", "スカイピース"
すると、ユーザーが「スカイピース」と検索した際に、OpenSearchが内部で「SKYPCE」も同義であると解釈し、関連するドキュメントを検索結果に含めてくれます。
シノニム機能が良かった点は、一度辞書を定義してしまえば、アプリケーション側で変換処理を実装することなく、OpenSearch側がよしなに同義語展開を行ってくれる開発の手軽さにあります。
これにより、表記ゆれの吸収といった課題をOpenSearchに任せることができます。
3. SKYPCEの要件とシノニム機能のフィットギャップ
検証を進める中で、シノニム機能は多くのシナリオで期待通りの結果を示してくれました。
しかし、今回実現すべき「会社名検索」の仕様に落とし込む際に、いくつかのギャップが明らかになってきました。
ギャップ1:データパイプラインのアーキテクチャ整合性
本機能の同義語データは、独立した辞書ファイルとして存在するのではなく、夜間バッチ処理によって生成・更新される正規化されたマスターデータの一部としてデータベースへ格納されます。
このアーキテクチャにおいて、OpenSearchが提供するS3連携ホットリロード機能を利用する場合、以下の課題が浮上しました。
- データ二重管理の発生: バッチ処理で生成したマスターデータから、同義語の部分だけを抽出し、OpenSearchが要求するテキストファイル形式に変換してS3にアップロードする、といった形でデータを二重管理する必要が出てきます。
- 同期と整合性の問題: データベース上のマスターデータと、S3上の同義語ファイルという2つのデータソースの同期を常に保証する必要があり、データパイプラインの複雑性と潜在的な不整合のリスクを高める構成になります。
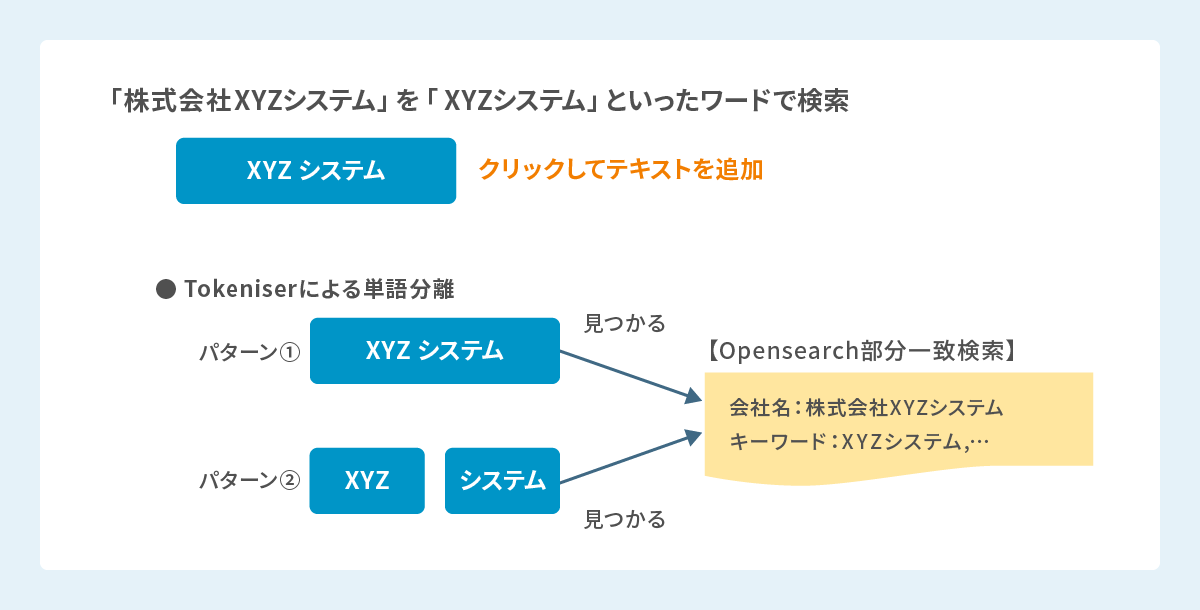
これらの点から、特定の機能のためにデータフローを分岐させてS3にファイルを配置するよりも、アプリケーションが単一の信頼できるプライマリデータベースを直接参照するアーキテクチャのほうが、システム全体のシンプルさ、堅牢性、および保守性において優れていると判断しました。
ギャップ2:形態素解析(kuromoji)とSynonym Filterの相互作用
技術的な観点をより深めると、採用見送りの理由の1つとして、日本語の形態素解析器(kuromoji)とSynonym Filterが相互作用する際の複雑性にありました。
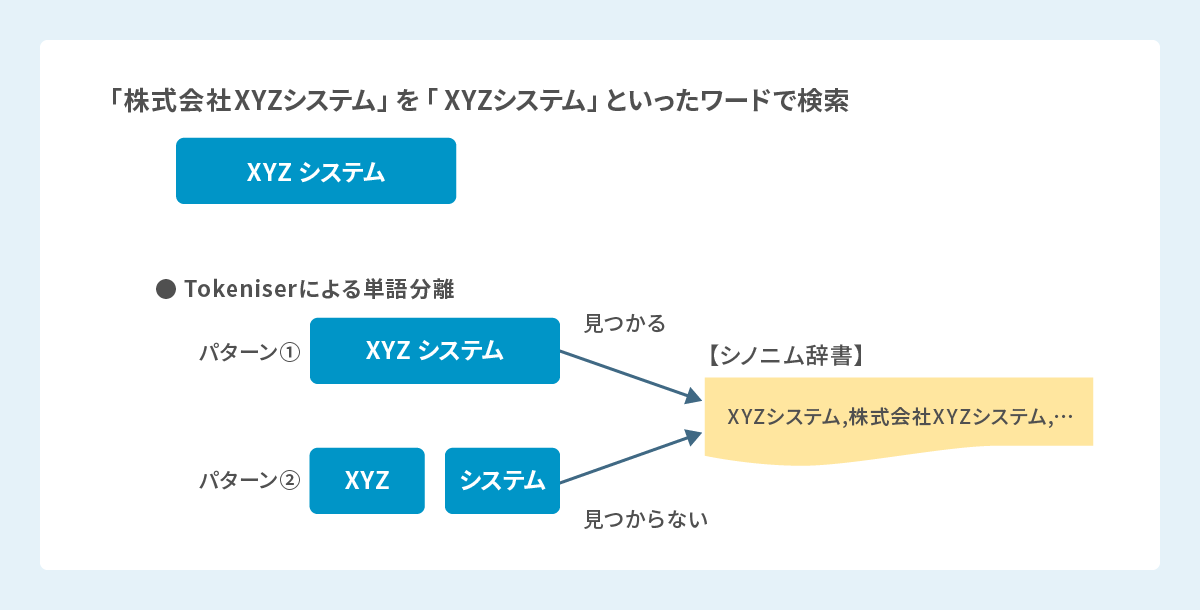
Synonym Filterは、Tokenizerによって分割された「トークン」に対して動作します。
例えば、正式名称が「株式会社XYZシステム」のデータに対して「XYZシステム」というワードで検索した際にこれを "kuromoji" で解析すると、"「XYZ」「システム」"のように分割される場合があります。 この時、「株式会社XYZシステム」に対して、「XYZシステム」という複数単語にまたがる同義語を定義しても、トークンがすでに分割されているため、期待通りにマッチしないケースが発生します。 仮にTokenizerがそのまま"「XYZシステム」"と分割すれば "「XYZシステム」=「株式会社XYZシステム」" だと解釈できますが、Tokenizerの挙動に依存する検索結果の揺れになります。
これを解決するには、"kuromoji" のユーザー辞書に「XYZシステム」を複合名詞として登録し、分割されないように制御した上で、Synonym Filterを適用する、といった二重のチューニングが必要となり、メンテナンスの複雑性が飛躍的に増大します。
さらに、"synonym_graph" フィルターとフレーズ検索("match_phrase")を組み合わせた際の挙動の予測の難しさも懸念点でした。
これらの技術的ハードルを考慮した結果、形態素解析後のトークンに対して外部から複雑な同義語ルールを適用するよりも、アプリケーション側で同義語展開を確定させてから、よりシンプルなクエリをOpenSearchに投げる方が、最終的な検索精度とシステムの予見性を確実に担保できると結論付けました。
最適な技術選定こそが、品質の礎となる
OpenSearchのシノニム機能は、その特性がマッチするユースケースにおいては、有用な機能です。
今回採用に至らなかったのは、あくまでSKYPCEの「会社名検索」という特定の要件において、よりフィットする別の選択肢があった、という技術選定の結果となりました。
一つの技術の優劣を語るのではなく、対峙している課題の特性を深く理解し、それに最も適した道具は何かを多角的に検証する。
この地道なプロセスこそが、製品の品質を支える礎になると、日々奮闘中です。
今後もSKYPCEは、OpenSearchをはじめとする様々な技術の長所を最大限に活かしながら、お客様により良いユーザーエクスペリエンスを提供できるよう、追求し続けていきます。
